Do Localhost para a Big Tech: A Saga da Certificação AWS GenAI (e o "Buraco Negro" do Fine-Tuning)
Vamos ser sinceros: até pouco tempo atrás, meu setup de IA era o equivalente digital a fazer fogo com duas pedras.
Eu estava lá, feliz, rodando chamadas para a SDK da OpenAI (ou API pura, como faziam os homens das cavernas), plugando coisas no LangGraph, PydanticAI e até brincando de Lego com N8N e FlowiseAI. Tudo isso é lindo, funciona e é super bacana para prototipar. Mas, no fundo, eu sentia que estava faltando uma peça chave no meu cinto de utilidades: Musculatura de Cloud Provider.
No meu day job, tive um contato breve com GCP e Apigee para gestão de APIs de LLM, mas foi aquele contato de elevador — rápido e superficial. A conclusão foi óbvia: para arquitetar soluções enterprise de verdade, eu precisava parar de brincar no localhost e dominar um gigante.
Por isso, tomei uma decisão questionável (mas necessária): vou encarar a AWS Certified Generative AI Developer Professional.
Detalhe: essa certificação ainda está em BETA. Isso significa que estou entrando em um campo minado onde tudo pode mudar, para que você não precise fazer isso. Vou documentar cada passo dessa dor de cabeça — digo, jornada de aprendizado — começando pelo elefante na sala: o AWS Bedrock.
O Ecossistema Bedrock (Mais que apenas um Wrapper)
Se você acha que o AWS Bedrock é só uma API bonitinha para chamar o Claude ou o Llama, você está meio certo, mas perdendo a imagem completa.
O Bedrock é o "canivete suíço" da AWS para GenAI. Ele permite acessar Foundation Models de vários providers (aqueles que têm contrato com a Amazon) numa interface unificada. Mas o "pulo do gato" não é o consumo, é a infraestrutura ao redor:
- Knowledge Base: A AWS facilitando o RAG. Você joga seus dados lá e ele gerencia a indexação vetorial (spoiler: falaremos disso no próximo post).
- Guardrails: A camada de segurança para evitar que seu bot ensine alguém a fazer napalm ou sofra Prompt Injection (leia: Como eu ganhei um iPhone 17 Pro hackeando uma IA).
- Agents: A orquestração da bagunça toda.
Mas hoje, o foco é onde a mágica (e o custo) acontece: Fine-Tuning.
Fine-Tuning: Quando o prompt não basta
Prompt Engineering é arte, mas tem limite. Às vezes você precisa mudar o comportamento intrínseco do modelo, ou ensinar um "dialeto" específico (como o "corporativês" interno da sua empresa ou relatórios de ações).
O Fine-Tuning é basicamente pegar um modelo genérico e mandá-lo para um bootcamp intensivo com seus dados. O problema? É um processo caro — tanto em dólares quanto em tempo de computação.
O "Alimento" do Modelo (JSONL)
Para criar um Custom Model no Bedrock, a "salsicha é feita" no S3. Você precisa preparar um dataset de treinamento (e validação) num formato JSONL específico. É aqui que muito engenheiro chora, porque a limpeza de dados é brutal.
O payload básico se parece com isso:
{"prompt": "Qual é o nome do país do futebol?", "completion": "É o Brasil!"}
{"prompt": "Quem vai derrubar a produção na sexta?", "completion": "O estagiário."}
BINGO! Você precisa de milhares desses pares para que o modelo comece a entender o padrão.
Instruction Tuning vs. Continued Pre-Training
A AWS divide isso em duas categorias que confundem muita gente:
- Instruction Tuning (O exemplo acima): Você dá o par
input+outputesperado. É o clássico "faça isso, responda aquilo". - Continued Pre-Training: Aqui a gente tira as rodinhas. Você não dá o par de perguntas e respostas (o labeling). Você apenas alimenta o modelo com toneladas de texto cru (documentos da empresa, livros, logs) para que ele se familiarize com o domínio. É como deixar o modelo lendo a enciclopédia da sua empresa antes de começar a trabalhar.
⚠️ Alerta de Segurança: Se você vai treinar um modelo com dados internos, pelo amor dos deuses da infraestrutura, use uma VPC com PrivateLink. Se você trafegar dados sensíveis pela internet pública para fazer training, seu time de InfoSec vai ter um ataque cardíaco.
A Mágica Matemática: LoRA (Não é apenas uma camada extra)
Aqui entra a parte onde a AWS brilha para não falir a gente. Re-treinar um LLM do zero exige um cluster de GPUs do tamanho de um estádio. Para contornar isso, o Bedrock utiliza LoRA (Low-Rank Adaptation).
Muita gente confunde e acha que LoRA é apenas "colocar um adaptador na frente do modelo". Errado.
Explicando de forma "simples": O LoRA congela os pesos do modelo original (que são gigantescos) e treina apenas pares de matrizes de baixo rank que representam a diferença necessária nos pesos.
A mágica acontece na hora de usar. O sistema não roda o modelo base e depois um adaptador sequencial (o que adicionaria latência). Ele faz um merge matemático. Ele soma as matrizes treinadas diretamente nas matrizes do modelo base.
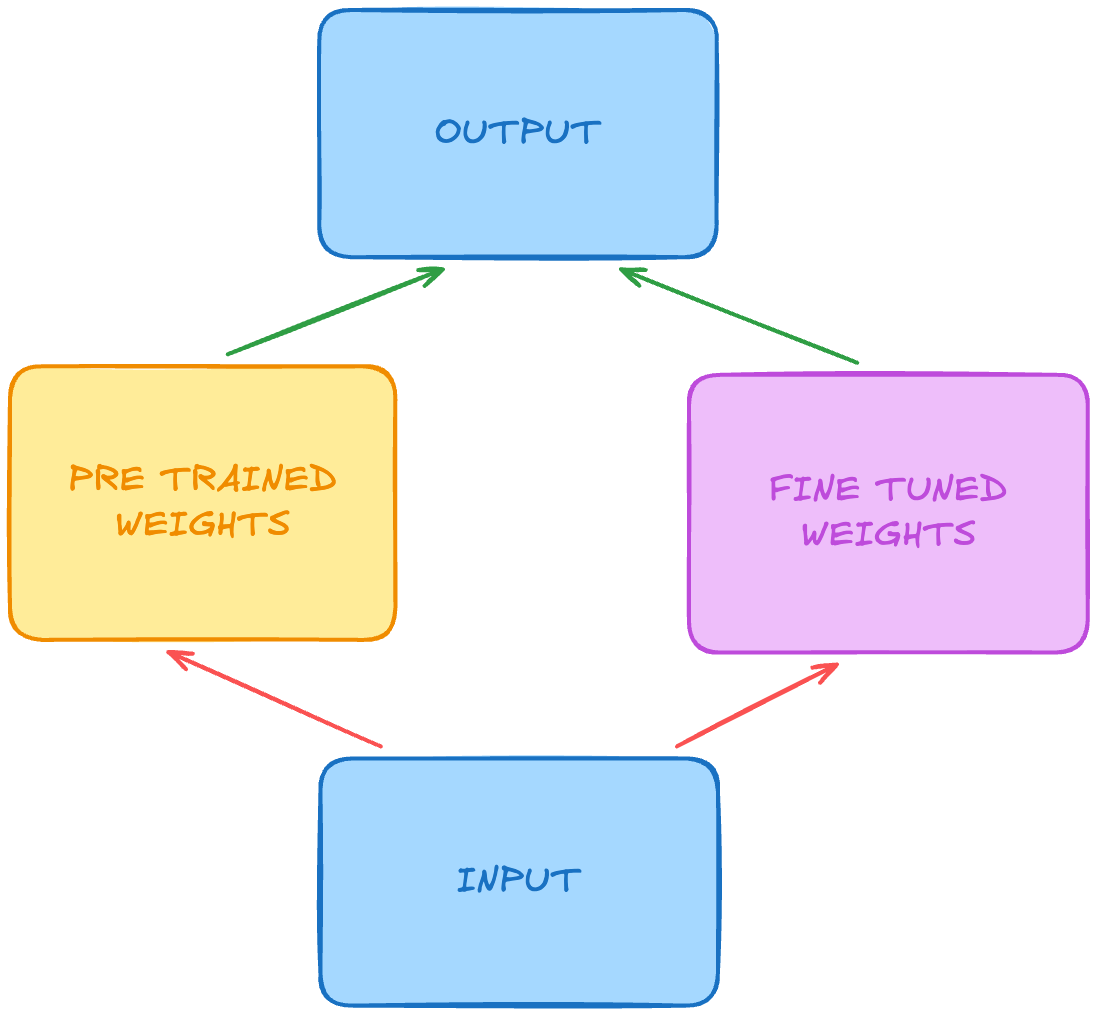
O resultado? Você tem um modelo que se comporta exatamente como se tivesse sido treinado por completo, mas você só precisou computar e armazenar uma fração minúscula dos parâmetros. É eficiência pura de inferência e storage.
O Veredito (Por enquanto)
O AWS Bedrock simplifica muito o processo de deploy e gestão de modelos customizados, abstraindo a dor de cabeça de gerenciar GPUs manualmente. Mas não se engane: a complexidade apenas mudou de lugar — saiu da infraestrutura e foi para a preparação dos dados e configuração de segurança na VPC.
Mas e se eu não quiser treinar o modelo? E se eu quiser apenas que ele acesse meus dados em tempo real? É aí que entra o RAG (Retrieval-Augmented Generation).
No próximo post, vamos dissecar o Knowledge Base do Bedrock e ver como conectar seus dados corporativos sem gastar uma fortuna em treinamento.
Próximo passo para você: Já teve que explicar para o seu chefe a diferença entre "treinar uma IA" e "conectar um PDF nela"?