O Dilema dos Vetores: Quando a Performance do OpenSearch encontra a Economia Real do S3

Sabe aquele momento em que você olha a conta da AWS no final do mês e percebe que seu cluster de OpenSearch Serverless está custando mais que o café gourmet da firma, mesmo quando ninguém está fazendo uma busca sequer? Pois é. Eu já estive lá.
No hype da IA Generativa, a gente tende a ir direto no "padrão ouro". Se você quer fazer RAG (Retrieval-Augmented Generation), o OpenSearch é o primeiro nome que surge na mesa. Mas a AWS recentemente jogou uma granada no mercado com os S3 Vectors. Agora, a pergunta não é mais apenas "como eu escalo?", mas "será que eu realmente preciso de uma Ferrari para ir à padaria?".
Abri o capô dessas duas soluções para entender onde a "salsicha técnica" é feita. Vamos aos fatos.
O Monstro do OpenSearch: Potência, Flexibilidade e... Boletos
O OpenSearch é o cara que resolve tudo, mas cobra o preço (literalmente). Ele é frequentemente tratado como a implementação principal para bases de conhecimento fundamentais, e não é por acaso. O bicho é robusto.
A Busca Híbrida é o real "Game Changer"
A maior vantagem aqui, e que me faz ainda amar o OpenSearch, é a Busca Híbrida. Enquanto a busca semântica (vetorial) tenta adivinhar o "significado" das coisas, ela às vezes viaja na maionese e perde termos específicos (como um código de erro ou um SKU de produto). O OpenSearch permite combinar o melhor dos dois mundos: Vetores + Palavras-chave tradicionais.
Nota de rodapé técnica: Isso exige indexar ambos simultaneamente, mas a relevância do resultado final é outra história. É a diferença entre o bot responder "Eu acho que é isso" e "É exatamente isso".
Debugando os Algoritmos (KNN)
Se você gosta de tunar o motor, o OpenSearch oferece três engines principais: FAISS, NMSLIB e Lucene. Como ninguém tem tempo (ou CPU) para fazer busca exata em milhões de vetores, a gente usa o ANN (Approximate Nearest Neighbor). Aqui moram dois caminhos:
- HNSW (Hierarchical Navigable Small World): É o velocista. Se você precisa de latência baixa, é ele. Mas prepare o bolso para a RAM, porque ele é faminto por memória. Você vai passar um bom tempo ajustando o parâmetro
m(densidade do grafo) e oef_construction. - IVF (Inverted File): O herói dos datasets massivos onde a RAM é limitada. Ele sacrifica um pouco do recall (precisão), mas mantém o servidor vivo.
Dica de Hacker: O Segredo dos Shards
Se você estiver fazendo só busca vetorial pura, vá de shards maiores (30-50 GB). Agora, se ativou a busca híbrida, mude para shards menores. A coordenação necessária para bater palavras-chave em muitos dados pode matar sua performance se o shard for um mamute.
S3 Vectors: O "Hacker Way" de Economizar 90%
Agora, vamos falar de vida real. Nem todo projeto de IA precisa responder em 20ms. Às vezes, você só quer que o bot do RH responda à política de férias sem que isso custe um rim.
O S3 Vectors é a resposta da AWS para quem quer simplicidade extrema. É bizarro: você cria um bucket vetorial, define as dimensões e pronto. A AWS gerencia a complexidade.
O "Pulo do Gato" no Custo
Dizem que ele pode ser até 90% mais barato que o OpenSearch. Por quê? Porque ele roda em cima da infra de baixo custo do S3. Não tem cluster ocioso drenando sua conta.
Mas calma, nem tudo são flores. O "preço" que você paga pela economia é o tempo.
- OpenSearch: Latência < 100ms.
- S3 Vectors: 100ms a 1 segundo.
Para um chatbot humano, 1 segundo é aceitável. Para um sistema de recomendação em tempo real num e-commerce? Esquece.
Como não passar raiva com S3 Vectors
Se você for por esse caminho, anote estas dicas de quem já quebrou a cara:
- Batching é Vida: Não envie vetores um por um. Use processamento em lote.
- Filtros Inteligentes: Marque metadados que você não vai usar em buscas como "não filtráveis". Isso limpa o overhead.
- Trate o Erro 429: Você vai bater no limite de throughput em algum momento. Implemente um mecanismo de retry decente no seu código.
O Veredito: Qual a sua briga?
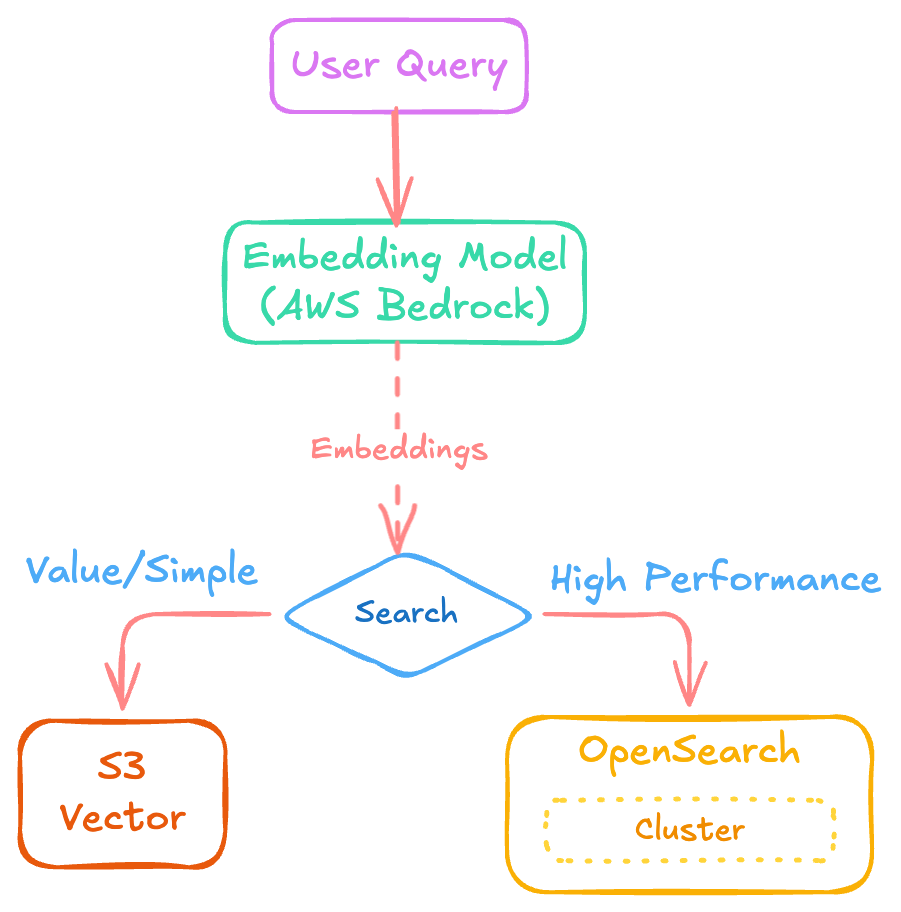
A AWS sugere uma estratégia em camadas que faz bastante sentido se você parar para pensar:
O Veredito: Lado a Lado
Para facilitar sua decisão na hora do deploy, resumi os pontos críticos que definem se você terá uma performance de elite ou uma economia massiva no final do mês:
- Latência (Velocidade de Resposta)
- Amazon OpenSearch: Ultra-rápida, com performance projetada para menos de 100ms. Ideal para aplicações de missão crítica e tempo real.
- Amazon S3 Vectors: Moderada, variando de 100ms a 1 segundo. É o suficiente para a maioria das bases de conhecimento padrão onde a velocidade extrema não é o requisito principal.
- Busca Híbrida (Keywords + Semântica)
- Amazon OpenSearch: O grande diferencial. Permite combinar busca vetorial com a tradicional pesquisa por palavras-chave para melhorar significativamente a relevância dos resultados.
- Amazon S3 Vectors: Focada na simplicidade da pesquisa vetorial nativa e integração direta.
- Complexidade de Gestão
- Amazon OpenSearch: Alta. Exige controle total sobre algoritmos (KNN), ajuste de shards e gerenciamento intensivo de memória RAM.
- Amazon S3 Vectors: Baixíssima. Totalmente gerenciado pela AWS, eliminando a complexidade de infraestrutura e otimização para o desenvolvedor.
- Custo no Final do Mês
- Amazon OpenSearch: Mais alto. Mesmo a opção serverless não significa custo zero quando o sistema está ocioso.
- Amazon S3 Vectors: Até 90% mais barato que o OpenSearch, aproveitando a infraestrutura de baixo custo do S3.
Onde eu coloco minhas fichas?
- Vá de OpenSearch se: Sua aplicação é mission-critical, você precisa de busca híbrida complexa ou tem usuários impacientes que não toleram um spinner de 1 segundo.
- Vá de S3 Vectors se: Você está montando uma base de conhecimento para documentos internos ("dados frios"), o orçamento está apertado ou você quer fazer um MVP funcional em 15 minutos.
Existe até um meio-termo: usar o OpenSearch como interface e o S3 Vectors como backend para dados menos acessados. É o melhor dos dois mundos para quem quer performance onde importa e economia onde dá. BINGO!