Esqueça o Fine-Tuning: Por que o RAG é o "Cérebro Real" da sua IA no AWS Bedrock
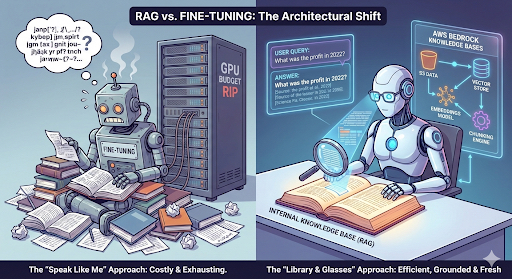
No último post, nós mergulhamos na toca do coelho do Fine-Tuning no AWS Bedrock. Foi divertido, poderoso e... caro. Se você leu aquilo e pensou "cara, isso dá muito trabalho só para fazer o bot ler meu PDF de RH", você está certo.
Hoje, vamos mudar a marcha. Eu vou te mostrar a alternativa arquitetural que a maioria das empresas realmente precisa, mas muitas vezes ignora por achar complexo demais: o RAG (Retrieval Augmented Generation).
Se o Fine-Tuning é ensinar a IA a "falar" como você, o RAG é dar a ela uma biblioteca inteira e os óculos para ler. E a melhor parte? O AWS Bedrock tem facilitado (e muito) a parte chata dessa engenharia.
Vamos ver como a salsicha é feita.
O Problema da "Amnésia" dos LLMs
Vamos ser honestos: LLMs são gênios presos no passado.
Se você perguntar para um modelo base (sem acesso à web) qual ação da bolsa subiu mais ontem, ele vai te olhar com aquele olhar vazio digital e dizer: "Meus dados de treinamento só vão até 2023". Ou pior, ele vai alucinar uma resposta convincente, mas totalmente falsa.
Agora, imagine que você quer que esse modelo responda sobre o relatório financeiro interno da sua empresa que saiu hoje de manhã.
- O modelo não foi treinado com isso (e nem deveria, por segurança).
- Você não vai re-treinar o modelo toda vez que um PDF novo for gerado (haja GPU!).
É aqui que entra o RAG.
A Injeção de Contexto (Prompt Injection do Bem)
O RAG resolve isso com um truque de ilusionismo técnico: nós recuperamos a informação relevante antes de falar com a IA e injetamos isso no contexto dela.
Em vez de perguntar "Como foi o lucro?", nós transformamos o prompt nisso aqui, por baixo dos panos:
<persona>
Você é um assistente especializado em relatórios da empresa Acme Inc.
</persona>
<goal>
Seu objetivo final é auxiliar o usuário com base APENAS no documento abaixo.
</goal>
<document>
{{TRECHO DO RELATÓRIO FINANCEIRO RECUPERADO DO VECTOR DB}}
</document>
<task>
Com base no documento recuperado, responda: Como foi o lucro?
</task>
BINGO! O modelo não "sabe" a resposta, ele apenas lê o que você mandou e resume.
Por que escolher RAG?
- Custo: Infinitamente mais barato que Fine-Tuning.
- Atualização: Subiu um arquivo no S3? O conhecimento está atualizado.
- Grounding: Reduz alucinações drasticamente, pois você obriga o modelo a citar a fonte.
A Engenharia por trás do AWS Bedrock Knowledge Bases
Até pouco tempo atrás, montar uma arquitetura RAG era uma dor de cabeça de integração: você precisava de scripts Python sujos conectando LangChain, Pinecone, OpenAI e AWS.
O Bedrock Knowledge Bases (KB) abstrai boa parte desse caos.
A arquitetura básica que montamos no Bedrock geralmente segue este fluxo:
- Fonte de Dados: S3 (com seus PDFs/JSONs), Salesforce, SharePoint ou até Web Crawlers.
- Vector Store: Onde os dados vivem. Pode ser o OpenSearch Serverless, Pinecone, Redis Enterprise ou Aurora (PGVector).
- Embeddings Model: O "tradutor" que transforma texto em números (ex: Amazon Titan Embeddings).
Pro Tip: Se você quer testar rápido, o Bedrock tem a feature "Chat with your document". Mas para produção, você vai querer usar a API ou os Agents para orquestrar isso.
O Segredo está no Chunking (Como fatiar a Salsicha)
Aqui é onde a maioria dos engenheiros erra. Você não pode simplesmente jogar um livro inteiro no prompt (limite de tokens e custo vão te matar). Você precisa quebrar o texto em pedaços menores, ou Chunks.
O Bedrock KB nos dá algumas opções nativas que valem a pena explorar. A escolha errada aqui destrói sua performance de recuperação.
1. Chunking de Tamanho Fixo (O Clássico)
Você define um número de tokens (ex: 300) e corta.
- Vantagem: Rápido, barato e previsível.
- O Pulo do Gato: Sempre use Overlap (sobreposição). Se cortar a frase no meio, o overlap garante que o contexto não se perca entre o chunk A e o B.
2. Hierarchical Chunking (Pai e Filho)
Essa é a minha favorita para documentos complexos.
- O sistema cria "Chunks Pais" (grandes) e "Chunks Filhos" (pequenos).
- A busca é feita nos filhos (mais precisos), mas na hora de entregar para o LLM, o sistema entrega o "Pai".
- Resultado: Você acha a agulha no palheiro, mas entrega o palheiro inteiro para a IA entender o contexto ao redor.
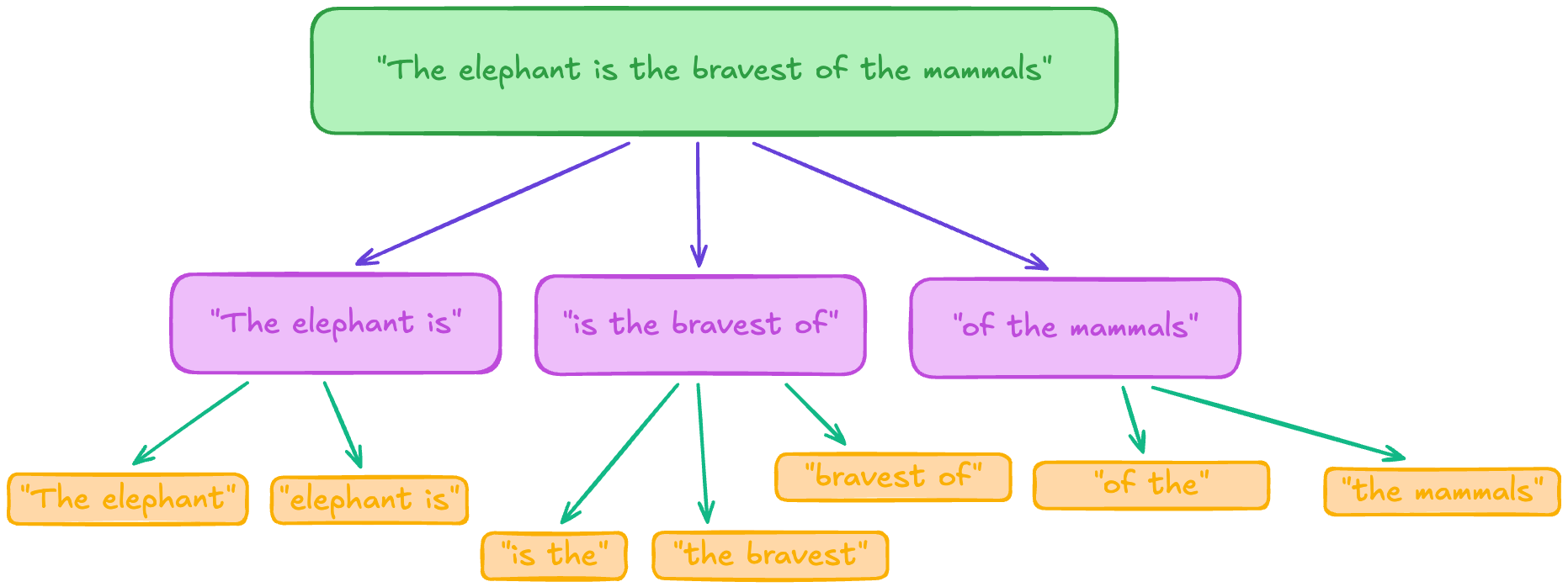
3. Semantic Chunking (O "Gourmet")
Aqui usamos um Foundation Model para ler o texto e decidir onde quebrar baseado no significado, não na contagem de palavras.
- Tradeoff: Custa mais caro (você paga pelo processamento do modelo) e é mais lento.
- Quando usar: Textos onde a nuance lógica é vital e parágrafos variam muito de tamanho.
Otimizando o "R" do RAG (Retrieval)
Não adianta ter o GPT-6 se o seu mecanismo de busca (Retrieval) só traz lixo. O sucesso do RAG é 80% busca e 20% geração.
Embeddings: Sparse vs Dense
- Sparse: Pense em busca por palavra-chave (TF-IDF). Bom para encontrar nomes específicos, códigos de erro, IDs.
- Dense: Vetores multidimensionais (o padrão do Amazon Titan). Capturam o significado. "Cachorro" e "Canino" ficam próximos matematicamente.
Atenção: Vetores menores (menos dimensões) são mais baratos e rápidos, mas perdem nuance. O Titan geralmente opera com 1024+. Se seu domínio é muito específico (ex: jurídico), não economize aqui.
Metadata Filtering (A Carta na Manga)
Essa é a feature mais subestimada. Em vez de buscar em todo o banco, use metadados.
No Bedrock, você pode passar um arquivo .metadata.json junto com o documento.
- Exemplo: O usuário pergunta "Qual o lucro de 2022?".
- Sem Metadata: A busca varre tudo.
- Com Metadata: Você filtra
year: 2022antes da busca vetorial. A precisão dispara.
Como saber se não está uma porcaria? (Avaliação)
"Achei que a resposta ficou boa" não é métrica de engenharia. O Bedrock agora inclui ferramentas de avaliação onde usamos o conceito de LLM as a Judge.
Basicamente, nós automatizamos um modelo (como o Claude ou Llama) para julgar as respostas do nosso sistema RAG com base em três pilares:
- Faithfulness (Fidelidade): A resposta inventou algo que não estava no texto recuperado? (Alucinação).
- Answer Relevance: A resposta realmente atende o que o usuário pediu?
- Context Precision: O chunk recuperado era realmente relevante?
Nós criamos um dataset de "Ground Truth" (perguntas e respostas ideais) e deixamos o script rodar. Se a pontuação cair, sabemos que nossa estratégia de chunking ou prompt precisa de ajuste.
Takeaway & Próximos Passos
RAG não é apenas "conectar um banco de dados". É uma disciplina de engenharia de dados que exige estratégia de pré-processamento.
Se você está começando agora no AWS Bedrock:
- Comece com o Chunking Padrão (Fixed) para estabelecer um baseline.
- Use o Amazon Titan para embeddings (custo-benefício excelente).
- Não ignore os metadados. Estruture seus arquivos no S3 de forma inteligente.
O futuro não é treinar modelos maiores, é conectar modelos inteligentes a dados bem curados.
E aí, já tentou implementar RAG e o modelo continuou alucinando?